使用Celery进行分布式计算
Celery介绍
Celery是一个基于Python的异步任务调度工具。全称是 Distributed Task Queue,分布式任务队列分布式决定了可以有多个worker存在,队列表示其是异步操作,即存在一个提出任务需求的生产车,和一堆等待执行任务的消费者。即典型的生产者消费者模式问题。
为了更形象的理解消息队列和生产者消费者模式,这里有一个比较有意思的类比:
1,生产者: 勤劳的妈妈 (User)
2,消息队列: 餐桌 (Broker)
3,消费者: 看着电视吃着饭的你 (Worker)妈妈做好饭以后,把饭菜放到餐桌上,代表生产者产生事件并放入消息队列。这个时候妈妈不需要等待,可以继续做下一道菜。解决了阻塞问题。
而看着电视的你,就是一个消费者,等你想吃饭了,直接从桌子上拿就可以了, 并且如果发现饭太多吃不完了,也可以召集所有肚子饿的兄弟姐妹一起吃,解决消费者处理能力的瓶颈问题。放到Celery上面就是增加Worker的服务器数量就可以了。
Celery的架构由四部分组成,任务发布者(User或者Task),消息中间件(Message Broker),任务执行单元(Worker)和任务执行结果存储(Backend)组成。
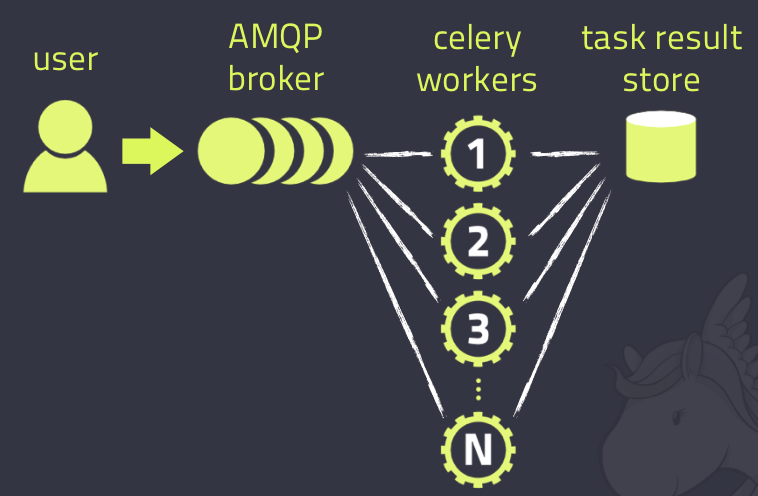
下面还有一个更详细的图:
1) 任务发布者(User或者Task) (相当于例子中的妈妈)
包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往任务队列,而定时任务由Celery Beat进程周期性地将任务发往任务队列。
2) 消息中间件(Message Broker)(相当于例子中的餐桌)
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。
包括:RabbitMQ,Redis,MongoDB等等。
3) 任务执行单元(Worker)(相当于例子中的你)
Worker是Celery提供的任务执行的单元,Worker并发的运行在分布式的系统节点中。
4) 任务结果存储(Backend)(例子里面没有相应的对应,如果非要说一个,那就是你告诉妈妈,吃饱了并写到一张纸上)
Backend用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, redis,memcached, mongodb,SQLAlchemy, Django ORM,Apache Cassandra, ronCache等。
这里需要注意一下,如果不配置backend,则任务执行后的结果是取不到的。所以如果你的任务是一个需要得到结果的话,必须配置backend对结果进行储存。
Celery及Redis的安装
首先需要安装消息中间件(在Celery帮助文档中称呼为中间人Broker,也就是例子的餐桌),可以安装RabbitMQ或者Redis。这里我们选择Redis作为Broker。想深入了解Redis,请参照这里。
安装Redis,它的安装比较简单。1
$ pip install redis
接下来安装Celery。1
$ pip install celery
注意,这里忽略了Python以及Pip的安装过程,请自行度娘。
Celery的HelloWorld
码农的习惯都一样,学习任何东西都想马上写一个HelloWorld出来,这里也不例外,我们实现一个最简单的HelloWorld。一共需要三个步骤:
- 定义任务函数。
- 运行Celery服务。
- 客户应用程序的调用。
首先,让我们来定义任务函数
[task.py]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 导入celery的包
from celery import Celery
# 配置Broker,这里选择Redis的数据库5
broker = 'redis://127.0.0.1:6379/5'
# 配置Backend,这里选择Redis的数据库6
backend = 'redis://127.0.0.1:6379/6'
# 启动Celery的服务
app = Celery('tasks', broker=broker, backend=backend)
# 定制一个加法任务(注意,这里的app是第10行定义的app)
def add(x, y):
return x + y
接下来,让我们运行Celery服务。1
2# 注意,其中的task就是task.py的文件名,否则找不到 其它的参数固定
celery -A task worker --loglevel=info
执行结果如下,说明启动成功: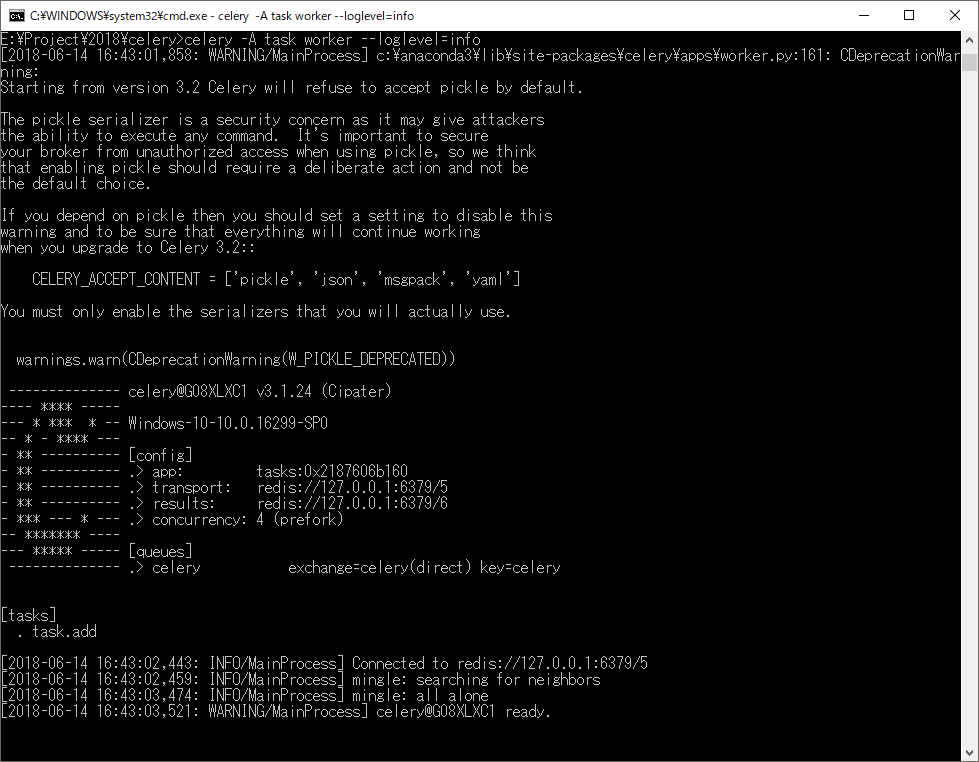
最后,在客户端完成Celery的调用。这里的客户端我们就选择普通的CMD来进行。
这里以Windows为例,我们先启动命令行程序,(注意要进入task.py相应的目录下),然后输入Python进入交互界面,就可以进行调用了。如下:1
2
3
4
5
6$ python
$ >>> from task import add
$ >>> res = add.delay(2, 2)
$ >>> <AsyncResult: 6fdb0629-4beb-4eb7-be47-f22be1395e1d>
$ >>> res.result
$ >>> 4
再附一张真正的执行结果: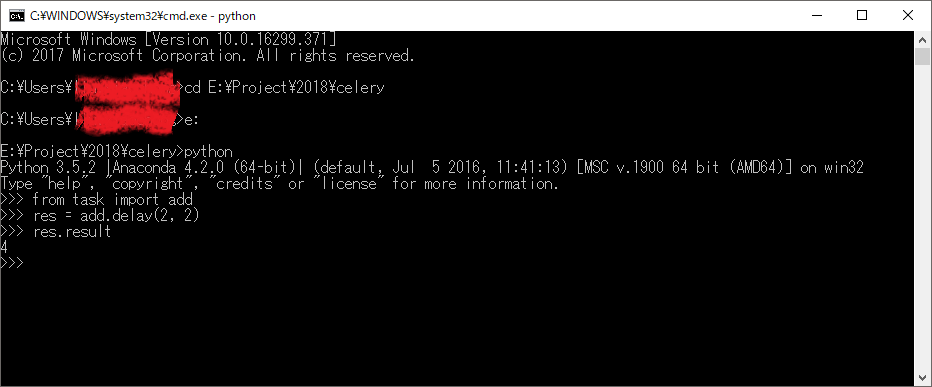
到此为止,一个简单的HelloWorld就完成了。 下面我们会继续深入。
Celery的继续深入
上面的HelloWorld里面,我们把所有的东西都放在了一个Python文件中,包括work和broker。
真正的项目开发中,我们肯定要分开管理,下面就用一个实例进行说明。
下面的例子中,我们的文件夹结构如下:1
2
3
4
5D:
└proj
├ celery.py #Celery的入口,名字必须是celery.py
├ config.py #Celery的配置类,名称任意,需要在celery.py指定该文件的路径
└ tasks.py #Celery的主要Worker类,所有的费时操作都会在这里处理,名称任意,需要在celery.py指定该文件的路径
下面是具体代码(说明请参照注释)
[celery.py]1
2
3
4
5
6
7
8
9
10
11
12
13#!/usr/bin/env python
# -*- coding=utf-8 -*-
from __future__ import absolute_import
from celery import Celery
# 引入Worker的处理类
app1 = Celery('proj1', include=['proj.tasks'])
# 通过配置文件创建服务
app1.config_from_object('proj.config')
# 启动celery的入口
if __name__ == '__main__':
app1.start()
[config.py]1
2
3
4
5
6
7
8#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
# 指定redis的数据库5作为Backend
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
# 指定redis的数据库6作为Broker
BROKER_URL = 'redis://127.0.0.1:6379/6'
[tasks.py]1
2
3
4
5
6
7
8
9
10
11
12
13
14#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
# 引入celery.py中创建的celery应用
# 由于app容易被误解成关键字,所以我这里特意改成了app1
from proj.celery import app1
import time
# 定义celery的任务
def add(x, y):
time.sleep(3) #模拟耗时操作
return x + y
下面开始启动celery
注意: 进入到proj所在的路径下执行,执行的时候指定proj,系统会自动查询celery.py启动服务。这里就是celery.py文件名固定的原因。
1 | celery -A proj worker -l info |
执行后结果如下。(测试方法可以参照上面的HelloWorld部分)
Celery的定时任务
Celery的调用方法有两种,第一种就是上面介绍的,通过程序进行调用,还有另外一种,是Celery提供了定时器功能,比如说每间隔10秒钟运行一次任务,或者每周一的早晨7点钟运行一次任务等等。
下面我们开始通过一个例子介绍这种机制。
首先看一下文件夹结构:1
2
3
4
5D:
└beatprj
├ celery.py #Celery的入口,名字必须是celery.py
├ config.py #Celery的配置类,名称任意,需要在celery.py指定该文件的路径
└ beat_tasks.py #Celery的主要Worker类,所有的费时操作都会在这里处理,名称任意,需要在celery.py指定该文件的路径
下面是具体代码(说明请参照注释)
[celery.py]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#!/usr/bin/env python
# -*- coding=utf-8 -*-
from __future__ import absolute_import, unicode_literals
from celery import Celery
from celery.task.schedules import crontab
from celery.decorators import periodic_task
#定义Celery,并指定tasks
app = Celery('beattask', include=['beatprj.beat_tasks'])
#指定配置文件
app.config_from_object('beatprj.config')
#第一种指定定时任务的方法,使用注解
def every_monday():
print("This runs every Monday for every minute")
#how to run: celery -A beatprj beat -l debug
if __name__ == '__main__':
app.start()
[config.py]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from datetime import timedelta
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/5'
BROKER_URL = 'redis://127.0.0.1:6379/6'
#第二种定义定时任务的方法,通过配置文件定制
CELERYBEAT_SCHEDULE = {
'my-schedule': {
'task': 'beatprj.beat_tasks.test', #指定调用的task
'schedule': timedelta(seconds=3), #指定调用间隔,这里是每3秒调用一次
'args': ('111',) #给任务函数传参,这里必须是一个turple
}
}
[beat_tasks.py]1
2
3
4
5
6
7
8
9#!/usr/bin/env python
# -*- coding:utf-8 -*-
from __future__ import absolute_import
from beatprj.celery import app
def test(mess):
print(mess)
下面开始启动celery
注意: 进入到beatprj所在的路径下执行,执行的时候指定beatprj,系统会自动查询celery.py启动服务。这里就是celery.py文件名固定的原因。
另外,这次角色要使用beat方式
1 | #以beat的方式启动 |
运行后结果如下:
可以看到,红框处已经设定好了两个定时器,并且下面也可以正常执行了。
总结
Celery是一个强大的分布式处理框架,这个文章里面只有几个简单的用法,涉及到一些复杂的应用,还是需要参考官网的详细说明。使用好了,绝对是你手中的一把利器。谢谢!